

Author(s): Gaurav Sharma
Semantic Segmentation: A Complete Guide
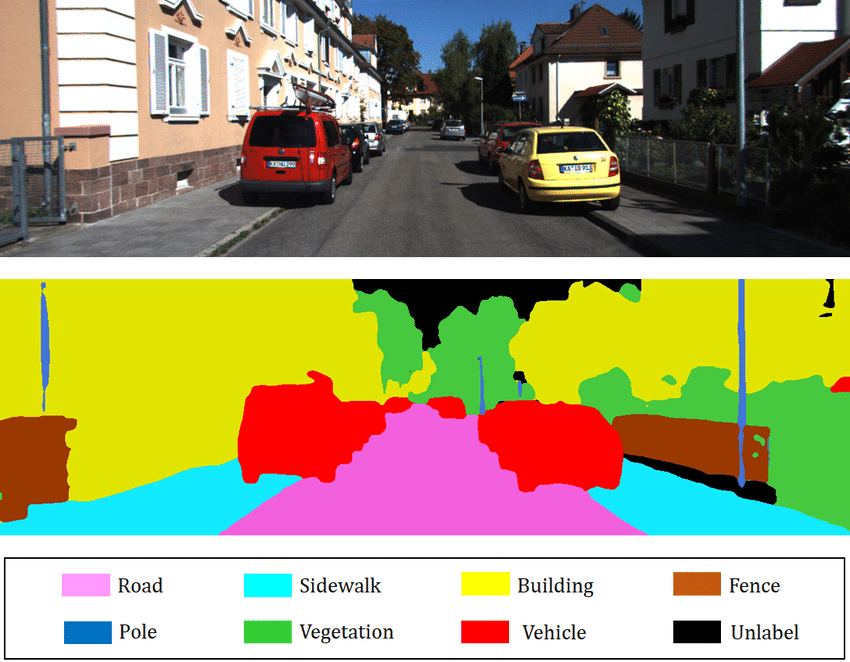 Image by: Author
Image by: Author
In computer vision, semantic segmentation is one of the most important components for fine-grained inference (CV). To achieve the appropriate precision levels, models must grasp the context of the environment in which they operate. As a result, through pixel accuracy, semantic segmentation supplies them with that insight.
Before we dig deep into the topic, let us understand what is semantic segmentation.
The goal of semantic segmentation is to group pixels in a meaningful way. Pixels that belong to a road, people, automobiles, or trees, for example, must be grouped individually. As a result, semantic segmentation does pixel-by-pixel categorization, such as determining if a pixel is part of a traversable road, an automobile, or a pedestrian. For self-driving automobiles and robotic navigation systems, this is critical.
Although semantic segmentation is described as the process of identifying and labeling images at the pixel level, it is sometimes mistaken for instance segmentation. The major difference is that with semantic segmentation, all pixels that belong to the same class have the same pixel value.
Difference between Semantic Segmentation and Instance segmentation
To give a broad overview, segmentation determines which object category it belongs to, whereas instance segmentation, as the name implies, recognizes instances by assigning unique labels to them. This is not about class recognition, but about instance recognition, which means the system is seeking the same lookalike object in the scene, and any objects that seem different, even if they belong to the same class as the item in question, are disregarded. This instance-level detection may be accomplished using lazy learning techniques: just store the description of the instance in a database, and during runtime, a matching score and a threshold are used to decide whether or not the instance is there.
Let’s take a look at an example: imagine there are numerous models of cars in the image you’re about to annotate. In this situation, semantic segmentation will recognize that the objects in a picture, in this case, cars, are models of the same class, whereas instance segmentation will give them separate instances. By quickly identifying objects of interest, both segmentation approaches have an impact across a wide range of sectors.
Semantic segmentation use cases
Semantic segmentation for computer vision is used in a variety of fields, including:
Recognizing people by their faces
Recognition of handwriting
Image search in the virtual world
Automobiles that drive themselves
Mapping for satellite and aerial imagery for the fashion industry and virtual try-on
Imaging and diagnostics in medicine
In general, semantic segmentation is utilized for more complex tasks than other image annotation methods, since it allows robots to generate a higher-level judgment. For a better understanding, we’ll look towards semantic segmentation common designs in the future.
Datasets for image segmentation
Machine learning (ML) models need to be exposed to a large amount of training data in order to get better and more dependable. Annotating hundreds or thousands of images by oneself or with a team isn’t always practicable, feasible, or cost-effective. Furthermore, if the model’s performance does not meet your project’s criteria, you will almost certainly have to retrain it. In that instance, you may require more training and testing data, which is where you need to outsource these services from professional firms.
Frameworks for image segmentation
We also scribbled down a list of frameworks you can utilize to level up your computer vision project for the sake of this article:
1. FastAI library: produces a mask of the objects in an image, helping to offer state-of-the-art solutions quickly and easily.
2. OpenCV is a free, open-source CV and machine learning toolkit with over 2500 algorithms.
3. The Sefexa image segmentation tool is a free tool for semi-automatic image segmentation, image analysis, and ground truth generation to test novel segmentation algorithms.
4. MiScnn is a Python library for medical image segmentation that is open-source.
5. For AR experiences on mobile devices, Fritz offers several image segmentation capabilities.
Popular structures with semantic segmentation
The CV community gradually developed applications for deep convolutional neural networks on more difficult tasks, such as object detection, semantic segmentation, keypoint detection, panoptic segmentation, and so on, after their tremendous success in the “ImageNet” challenge. The evolution of semantic segmentation networks began with a minor tweak to the state-of-the-art (SOTA) classification models. The customary fully connected layers at the end of these networks were replaced with 1×1 convolutional layers, and to project back to the original input size, a transposed convolution (interpolation followed by a convolution) was added as the last layer.
The first effective semantic segmentation networks were these basic fully convolutional networks (FCNs). U-Net took the next big step forward by introducing encoder-decoder topologies that also used residual connections, resulting in finer-grained and crisper segmentation maps. These big architectural concepts were followed by a slew of lesser modifications, resulting in a dizzying array of buildings, each with its own set of advantages and disadvantages.
The most important takeaways
In semantic segmentation, we go a step further and group image segments that are typical of the same object class together. As a result, the image is separated into many parts, allowing machine learning models to better contextualize and forecast the input data. We hope that this essay has helped you gain a better grasp of the subject. If you require additional information at any point along the annotation workflow, please do not hesitate to contact us. Have fun on the ride!
Our Suggestions
A brush or a polygon can be used to do manual semantic segmentation. Some tools have a number of options for modifying the brush’s form and size to make the process run faster, however polygons are commonly used to obtain higher precision.
In settings when it’s crucial to know how many units of a particular object are present, instance (or “instance-aware”) segmentation may be preferable. It employs the same panoptic segmentation principle, but each instance is given its own class and color.
Some tools allow you to draw on top of or underneath existing masks to make segmentation of nearby items easier. This ensures that no pixels are lost in between and makes drawing the second mask easy.
Machine Learning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI