

Pengarang: Mahisha Patel
Bagaimana Pengumpulan Data AI
bekerja dalam kaitannya dengan Mesin
Model Pembelajaran?
Apakah Anda berencana untuk memperkenalkan AI ke skema organisasi yang ada? Atau apakah Anda hanya ingin menyiapkan pengaturan yang cerdas dan otonom untuk memenuhi basis pengguna tertentu? Terlepas dari apa yang ingin Anda capai sehubungan dengan implementasi AI, itu tidak dapat diubah kecuali Anda memiliki data yang relevan untuk diandalkan.
Pentingnya Pengumpulan Data AI
Pengumpulan data sebagai topik tidak ada habisnya. Tetapi kemudian, bagi yang belum tahu, ini dapat dipahami secara sederhana sebagai proses memperoleh informasi khusus model untuk melatih algoritme AI dengan lebih baik, sehingga mereka dapat mengambil keputusan proaktif dengan otonomi.
Cukup sederhana, kan! Nah, ada lebih dari itu. Bayangkan calon model AI Anda sebagai seorang anak, tidak menyadari bagaimana subjek bekerja. Untuk mengajari anak membuat panggilan dan menyelesaikan tugas, Anda harus membuatnya mempelajari konsepnya terlebih dahulu. Inilah yang ingin dicapai oleh kumpulan data di AI, dengan bekerja sebagai dasar bagi model untuk dipelajari.
Jenis Dataset yang Relevan dengan Proyek AI
Mengumpulkan banyak data ke dalam kumpulan data yang relevan tidak masalah, tetapi apakah setiap kumpulan data dimaksudkan untuk melatih model. Tidak persis seperti ada tiga kategori kumpulan data yang lebih luas yang perlu diketahui sebelum mencari wawasan yang relevan.
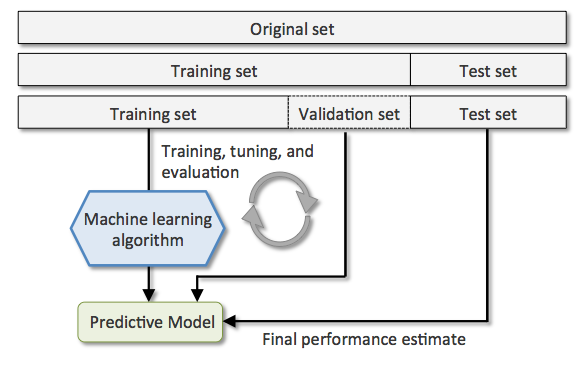
Kumpulan data AI terutama digunakan untuk melatih algoritme dan akhirnya model itu sendiri. Set data pelatihan membuat 60% dari keseluruhan data yang dikumpulkan relevan dengan pembelajaran mesin dan model pengajaran tentang jaringan saraf, pembelajaran mandiri, dan banyak lagi.
2. Kumpulan Data Uji
Menguji data penting untuk melihat seberapa baik model telah memahami konsep. Namun, karena model ML telah dimasukkan dalam volume besar data pelatihan, yang diharapkan dapat dikenali oleh algoritme pada tahap pengujian, set data pengujian harus benar-benar berbeda dan tidak sinkron dengan hasil yang diharapkan.
3. Set Validasi
Setelah model dilatih dan diuji, Anda perlu menambahkan set validasi untuk memastikan bahwa produk akhir menjadi sempurna dan sesuai dengan harapan.
Strategi apa yang harus diikuti untuk Pengumpulan Data AI?
Sekarang setelah Anda mengetahui jenis kumpulan data, penting untuk menyusun rencana yang terukir dengan baik untuk membuat pengumpulan data AI sukses.
Strategi 1: Temukan Jalan
Tidak ada masalah yang lebih besar daripada Anda tidak mengetahui titik awal pengumpulan data untuk model prediksi Anda. Setelah tim R&D membuat prototipe visual, penting untuk merencanakan strategi yang melampaui penimbunan data.
Sebagai permulaan, disarankan untuk mengandalkan kumpulan data terbuka, terutama yang ditawarkan oleh penyedia layanan yang kredibel. Plus, fokus Anda harus hanya memberi data yang relevan dengan model dan menjaga kompleksitas seminimal mungkin, terutama saat memulai.
Strategi 2: Mengartikulasikan, Menetapkan, dan Memeriksa
Setelah Anda tahu dari mana mendapatkan data, Anda harus mengartikulasikan aspek prediktif model sebelumnya. Di sinilah eksplorasi data terjadi dan pada titik ini Anda harus menetapkan algoritme yang mungkin relevan dengan sistem Anda. Anda dapat memilih antara algoritma pengelompokan, regresi, klasifikasi, dan peringkat.
Selanjutnya, Anda harus membuat mekanisme untuk pengumpulan data, dengan opsi yang memungkinkan adalah Data Lakes, Data Warehouses, dan ETL. Terakhir, pengumpulan data yang lebih baik juga mengharuskan Anda untuk memeriksa kualitasnya dengan memastikan kecukupan, keseimbangan atau kekurangannya, dan kesalahan teknis, jika ada.
Strategi 3: Format dan Kurangi
Jelas bahwa Anda ingin melatih, menguji, dan memvalidasi model Anda dengan mengumpulkan data dari sumber yang berbeda. Oleh karena itu, penting untuk memformatnya di awal, hanya demi konsistensi dan memperbaiki rentang operasi.
Selanjutnya, Anda harus mengurangi kumpulan data agar cukup berfungsi. Tapi tunggu, bukankah cadangan data yang tak ada habisnya disarankan untuk mengembangkan model cerdas. Ya, tetapi jika Anda berencana untuk mengerjakan tugas-tugas eksklusif, mengurangi data melalui pengambilan sampel atribut, adalah cara yang harus dilakukan.
Anda dapat melakukan reduksi data lebih lanjut dengan melengkapinya dengan pembersihan data, menggunakan alat seperti pengambilan sampel rekaman yang memotong rekaman yang salah dan hilang dari database.
Strategi 4: Pembuatan Fitur
Strategi ini masuk akal jika Anda berurusan secara spesifik seperti pengumpulan data gambar atau pengumpulan data ucapan dalam hal ini. Meskipun menambahkan banyak data bersih dan dikurangi adalah penting karena Anda tidak ingin memasukkan gambar yang tidak lengkap dan buram ke model, Anda harus mencoba dan memastikan bahwa fitur khusus tertentu dibuat dengan cara yang dipesan lebih dahulu untuk membuat model lebih intuitif. pada waktunya.
Strategi 5: Skalakan Ulang dan Diskrit
Pada saat Anda berada di titik ini, Anda diharapkan telah mengumpulkan semua data relevan yang masuk akal. Namun, Anda masih perlu mengubah skala yang sama untuk meningkatkan kualitas koleksi diikuti dengan mendiskritkan hal yang sama untuk membuat prediksi lebih tajam dan lebih relevan.
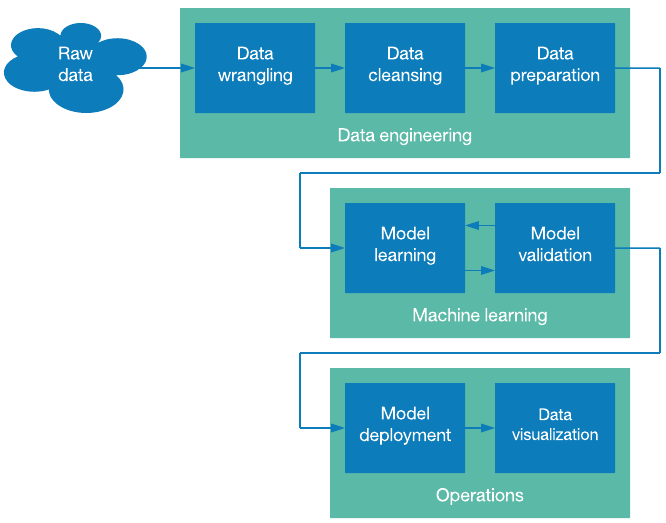
Bungkus
Pengumpulan Data bukanlah proses yang mudah. Ini membutuhkan banyak pengalaman dan seringkali tim insinyur dan ilmuwan data yang berpengalaman dan terampil. Baik itu mempersiapkan model visi komputer dengan pengumpulan data video dan gambar atau sistem NLP dengan pengumpulan data ucapan dan teks, perusahaan harus fokus untuk terhubung dengan penyedia layanan terkenal untuk mengalihdayakan pengumpulan data, segera.
Referensi
https://www.shaip.com/offerings/data-collection/ https://www.iotforall.com/effective-tips-to-build-a-training-data-strategy-for-machine-learning
Terima kasih telah membaca! Semoga harimu menyenangkan!! 🙂
Kecerdasan Buatan awalnya diterbitkan di Towards AI on Medium, di mana orang-orang melanjutkan percakapan dengan menyoroti dan menanggapi cerita ini.
Diterbitkan melalui Menuju AI

Komputer PC Desktop HP Elite Intel Core i5 3.1-GHz, Ram 8 gb, Hard Drive 1 TB, DVDRW, Monitor LCD 19 Inci, Keyboard, Mouse, WiFi Nirkabel, Windows 10 (Diperbarui)
$215,99 (per 11 November 2021 16:16 GMT -05:00 – Info lebih lanjutHarga dan ketersediaan produk akurat pada tanggal/waktu yang ditunjukkan dan dapat berubah. Informasi harga dan ketersediaan apa pun yang ditampilkan di [relevant Amazon Site(s), as applicable] pada saat pembelian akan berlaku untuk pembelian produk ini. %site_host% adalah peserta dalam Program Associates Amazon Services LLC, program periklanan afiliasi yang dirancang untuk menyediakan sarana bagi situs untuk mendapatkan biaya komisi dengan mengiklankan dan menautkan ke situs web berikut. %associates_list%)