

Namun, kemajuan terbaru dalam AI telah mengkonfirmasi keyakinan ini salah — sebagai gantinya, membangun titik awal yang “cukup baik” untuk sebuah model telah memungkinkan praktisi untuk membuat sejumlah besar pelatihan lebih lanjut, validasi, dan peningkatan akurasi sementara juga memungkinkan wawasan yang lebih dalam inti dari data yang digunakan.
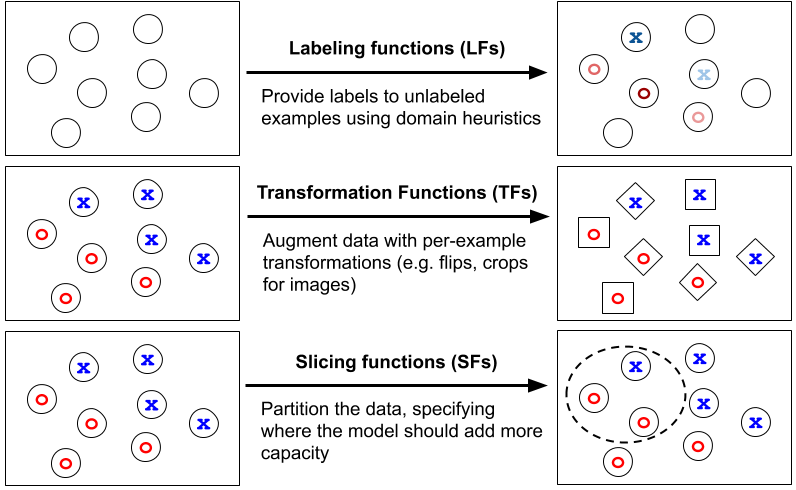
Organisasi dan perusahaan AI mulai mengubah dan memfokuskan upaya mereka ke arah pendekatan AI yang lebih berpusat pada data, berbeda dengan pendekatan yang berpusat pada model ketika mereka mulai menyadari bahwa pendekatan yang berpusat pada data (juga disebut sebagai Perangkat Lunak 2.0) untuk ML pipeline sangat penting untuk meningkatkan akurasi dan pengembangan aplikasi AI yang cepat.
Lanskap AI beralih dari model-sentris menuju AI data-sentris, dan sementara ada beberapa cara keren untuk mendekatinya, orang-orang di Snorkel AI akan bekerja sama dengan Snorkel Flow, platform AI pertama yang benar-benar data-sentris, dengan akar dalam pemrograman data tercanggih dan pendekatan pengawasan yang lemah yang bertujuan untuk mengatasi tantangan besar dalam mengalihkan praktik AI saat ini ke pendekatan data-sentris yang lebih kuat dan mengakhiri modelitis yang membuang-buang waktu.
Dalam bacaan singkat ini, kita akan berbicara tentang Snorkel AI. Para penemu di balik pendekatan AI yang berpusat pada data:
 Sumber: Snorkel AI
Sumber: Snorkel AI
Tentang Snorkel AI
Snorkel AI dimulai sebagai proyek penelitian di Stanford AI Lab pada tahun 2015. Awalnya berangkat untuk menjelajahi antarmuka tingkat yang lebih tinggi untuk pembelajaran mesin melalui data pelatihan. Snorkel AI memiliki lebih dari 50 publikasi peer-review, diterbitkan di ICML, Nature, ICLR, IEEE, NeurIPS, dan banyak lagi, yang mendukung teknologi inti di balik Snorkel Flow. Selain itu, teknologi Snorkel telah dikembangkan dengan dan diterapkan di Google, Intel, Apple, dua dari tiga bank teratas AS, Departemen Kehakiman AS, dan organisasi terkemuka lainnya.
 Sumber: Snorkel AI
Sumber: Snorkel AI
Snorkel Flow, Platform AI Berpusat Data Pertama
Snorkel Flow adalah platform pengembangan AI yang didukung oleh pengawasan yang lemah [2], dan pelabelan data terprogram [3] pendekatan. Menggunakan Snorkel Flow, tim ilmu data dapat berkolaborasi dengan pakar materi pelajaran untuk membangun aplikasi AI yang sangat akurat dengan cepat. Selain itu, ini memungkinkan pengguna untuk membuat dan mengelola sejumlah besar data pelatihan, melatih model, menganalisis, meningkatkan kinerja dengan mengulangi tidak hanya pada model tetapi juga data pelatihan dan penerapan — semuanya dalam satu platform.
 Sumber: Snorkel AI
Sumber: Snorkel AI
Di Mana Aliran Snorkeling Unggul?
Beri label dan buat data pelatihan secara terprogram dalam hitungan jam, bukan berbulan-bulan atau bahkan bertahun-tahun dengan pelabelan tangan. Integrasikan dan kelola data pelatihan terprogram dari semua sumber, termasuk pembersihan data dan pemotongan data. Latih dan terapkan model pembelajaran mesin tercanggih dalam platform atau melalui Python SDK. Analisis dan pantau kinerja model untuk mengidentifikasi dan memperbaiki mode kesalahan dalam data dengan cepat.
Pelajari lebih lanjut tentang platform Snorkel Flow.
 Sumber: Snorkel AI
Sumber: Snorkel AI
Studi Kasus SuperGLUE
Menggunakan model standar (yaitu, BERT pra-terlatih) dan penyetelan minimal, tim AI Snorkel mampu memanfaatkan abstraksi kritis untuk membangun dan mengelola data pelatihan secara terprogram guna mencapai hasil mutakhir pada SuperGLUE — tolok ukur yang baru dikuratori ; dengan enam tugas untuk mengevaluasi “teknologi pemahaman bahasa tujuan umum.
SOTA baru dicapai dengan menggunakan abstraksi pemrograman pada SuperGLUE Benchmark dan empat tugas komponennya. SuperGLUE mirip dengan GLUE tetapi berisi “tugas yang lebih sulit, yang dipilih untuk memaksimalkan kesulitan dan keragaman. Tugas-tugas ini dipilih untuk menunjukkan kesenjangan ruang kepala yang substansial antara baseline berbasis BERT yang kuat dan kinerja manusia.”
 Sumber: Snorkel AI
Sumber: Snorkel AI
Setelah mereproduksi baseline BERT++, kami menyesuaikan model ini secara minimal (model dasar, kecepatan pembelajaran default, dan sebagainya.) dan menemukan bahwa dengan aplikasi abstraksi pemrograman di atas, kami melihat peningkatan +4.0 poin pada benchmark SuperGLUE (menunjukkan 21 % pengurangan kesenjangan dengan kinerja manusia).
Kertas [5] juga memberikan pembaruan pada kasus penggunaan industri Snorkel dengan lebih banyak aplikasi dalam skala, misalnya, Google di Snorkel Drybell untuk karya ilmiah dalam klasifikasi MRI dan kurasi studi asosiasi Genome-wide (GWAS) otomatis, keduanya diterima di Nature Comms.
Studi Kasus Industri
Google telah menggunakan Snorkel untuk mengganti lebih dari 100 ribu label beranotasi tangan dalam alur pembelajaran mesin yang penting. Sebuah bank top AS menggunakan Snorkel Flow untuk dengan cepat membangun aplikasi AI yang mengklasifikasikan dan mengekstrak informasi dari dokumen mereka. Apple membangun aplikasi dengan sistem berbasis Snorkel internal yang menjawab miliaran pertanyaan dalam berbagai bahasa dan memproses triliunan catatan dengan kesalahan hingga 2,9x lebih sedikit. Pelopor Fortune 500 Biotech memanfaatkan Snorkel Flow untuk mengekstrak data penyakit kronis kritis dari uji klinis, memproses 300 ribu dokumen secara akurat dalam hitungan menit.
Referensi
[1] “Snorkel: Pembuatan Data Pelatihan Cepat dengan Pengawasan Lemah.” Alex Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, Chris Re, Universitas Stanford, https://arxiv.org/pdf/1711.10160.pdf
[2] “Pengawasan yang Lemah: Paradigma Pemrograman Baru Untuk Pembelajaran Mesin.” Alex Ratner, Paroma Varma, Braden Hancock, Chris Ré, dkk., SAIL Blog, 2019, https://ai.stanford.edu/blog/weak-supervision/
[3] “Pelabelan Terprogram Interaktif untuk Pengawasan yang Lemah.” Benjamin Cohen-Wang, Stephen Mussmann, Alex Ratner, Chris Ré, KDD, 2019, https://bencw99.github.io/files/kdd2019_dcclworkshop.pdf
[4] “Snorkel DryBell: Studi Kasus dalam Menyebarkan Pengawasan yang Lemah pada Skala Industri.” Stephen H. Bach, Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Cassandra Xia, Souvik Sen, Alexander Ratner, Braden Hancock, Houman Alborzi, Rahul Kuchhal, Christopher Ré, Rob Malkin, SIGMOD, 2019, https://arxiv .org/abs/1812.00417
[5] Wang, Alex, dkk. “SuperGLUE: Tolok Ukur Lebih Lengket untuk Sistem Pemahaman Bahasa Tujuan Umum.” 2019. SuperGLUE terdiri dari 6 set data: Commitment Bank (CB, De Marneffe, et al., 2019), Choice Of Plausible Alternatives (COPA, Roemmele, et al., 2011), dataset Multi-Sentence Reading Comprehension (MultiRC, Khashabi, dkk., 2018), Mengenali Entailmen Tekstual (digabung dari RTE1, Dagan dkk. 2006, RTE2, Bar Haim, dkk., 2006, RTE3, Giampiccolo, dkk., 2007, dan RTE5, Bentivogli, dkk. al., 2009), Word in Context (WiC, Pilehvar, dan Camacho-Collados, 2019), dan Winograd Schema Challenge (WSC, Levesque, et al., 2012).