

Pengarang: Nirmal Maheshwari
Awalnya diterbitkan di Towards AI the World’s Leading AI and Technology News and Media Company. Jika Anda sedang membangun produk atau layanan terkait AI, kami mengundang Anda untuk mempertimbangkan untuk menjadi sponsor AI. Di Towards AI, kami membantu menskalakan AI dan startup teknologi. Biarkan kami membantu Anda melepaskan teknologi Anda kepada massa.
Pembelajaran mesin
Hidup ini penuh dengan keputusan dan akhirnya, kita mengukur pilihan mana yang harus diambil berdasarkan beberapa analisis berbasis logika. Dalam rangkaian blog ini, kita akan membuat diri kita nyaman dengan dua model pembelajaran mesin yang sangat populer — pohon keputusan dan hutan acak.
Untuk blog ini, kami akan membatasi diri pada Pohon keputusan dan kemudian beralih ke Random Forest salah satu algoritma yang paling banyak digunakan di industri ini. Kami juga akan memahami bagian pengkodean bisnis dengan memecahkan contoh dunia nyata. Jadi ayo mulai.
Intuisi di balik Pohon Keputusan
Dengan kemampuan interpretasi yang tinggi dan algoritme intuitif, pohon keputusan meniru proses pengambilan keputusan manusia dan unggul dalam menangani data kategorikal. Tidak seperti algoritma lain seperti regresi logistik atau SVM, pohon keputusan tidak menemukan hubungan linier antara variabel independen dan variabel target. Sebaliknya, mereka dapat digunakan untuk memodelkan data yang sangat nonlinier.
Ini adalah algoritma pembelajaran yang diawasi dan Anda dapat dengan mudah menjelaskan semua faktor yang mengarah pada keputusan/prediksi tertentu. Oleh karena itu, mereka mudah dipahami oleh para pebisnis. Mari kita pahami ini dengan contoh Sistem Persetujuan Pinjaman di bawah ini
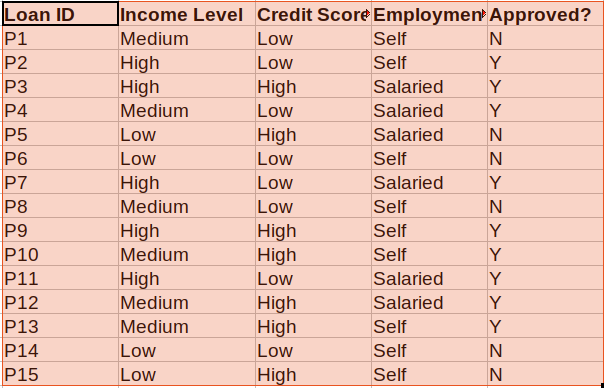 Dataset Pinjaman
Dataset Pinjaman
Kita perlu mengambil keputusan berdasarkan data historis ini jika ada catatan baru, apakah orang itu memenuhi syarat untuk mendapatkan pinjaman atau tidak. Mari kita visualisasikan pohon keputusan untuk kumpulan data di atas
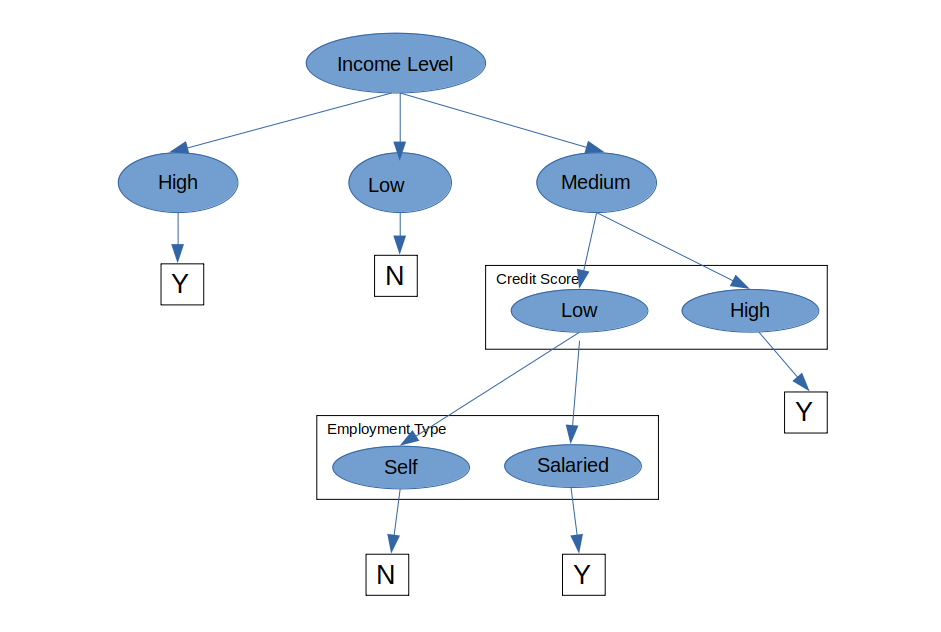 Pohon Keputusan Persetujuan Pinjaman
Pohon Keputusan Persetujuan Pinjaman
Anda dapat melihat bahwa pohon keputusan menggunakan proses pengambilan keputusan yang sangat alami: mengajukan serangkaian pertanyaan dalam struktur if-then-else bersarang.
Pada setiap node, Anda mengajukan pertanyaan untuk membagi lebih lanjut data yang disimpan oleh node tersebut. Jika tes lulus, Anda ke kiri; jika tidak, Anda ke kanan. Kami membagi di setiap node sampai kami tidak mendapatkan subset murni atau mencapai keputusan.
Menafsirkan Pohon Keputusan
Mari kita memahami di atas dalam hal pohon keputusan.
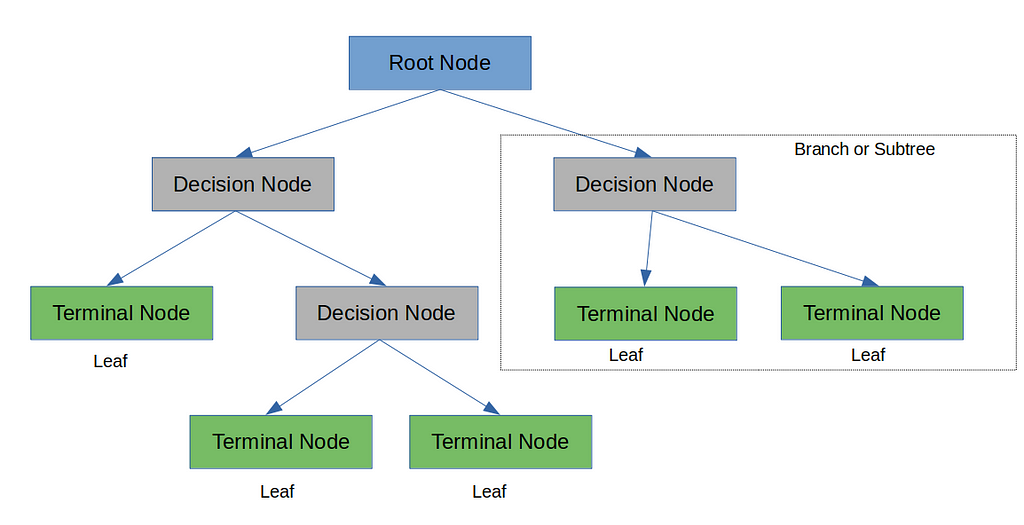 Pohon Keputusan
Pohon Keputusan
Pada setiap Decision Node, pengujian dilakukan terkait dengan salah satu fitur dalam dataset dan jika pengujian tersebut lulus maka akan menuju ke satu sisi pohon jika tidak ke sisi lain. Hasil tes akan membawa kita ke salah satu cabang pohon dan untuk masalah klasifikasi setiap daun akan berisi salah satu kelas.
Pohon keputusan biner adalah tempat kami menguji membagi dataset menjadi dua bagian seperti memutuskan berdasarkan jenis pekerjaan dalam contoh di atas. Sekarang jika ada atribut yang memiliki 4 macam nilai dan tergantung pada setiap nilai saya ingin membuat keputusan maka itu akan menjadi pohon keputusan multiway.
Pohon keputusan mudah diinterpretasikan. Hampir selalu, Anda dapat mengidentifikasi berbagai faktor yang mengarah pada keputusan tersebut. Pohon sering diremehkan karena kemampuannya untuk menghubungkan variabel prediktor dengan prediksi. Sebagai aturan praktis, jika interpretasi oleh orang awam adalah apa yang Anda cari dalam sebuah model, pohon keputusan harus berada di bagian atas daftar Anda.
Regresi dengan Pohon Keputusan
Dalam masalah regresi, pohon keputusan membagi data menjadi beberapa himpunan bagian. Perbedaan antara klasifikasi pohon keputusan dan regresi pohon keputusan adalah bahwa dalam regresi, setiap daun mewakili model regresi linier, berlawanan dengan label kelas. Untuk blog ini, kami akan membatasi diri pada masalah klasifikasi tetapi saya akan menyebutkan poin-poin tertentu untuk regresi juga jika diperlukan.
Algoritma untuk Konstruksi Pohon Keputusan
Mari kita pahami bagaimana pohon keputusan mengetahui atribut mana yang harus diambil terlebih dahulu?
Konsep Homogenitas
Secara umum, aturan mengatakan bahwa kita harus mencoba dan membagi node sedemikian rupa sehingga node yang dihasilkan sehomogen mungkin, yaitu semua baris milik satu kelas setelah pemisahan. Jika simpul adalah tingkat pendapatan dalam contoh di atas, coba dan bagi dengan aturan sedemikian rupa sehingga semua titik data yang melewati aturan memiliki satu label (yaitu sehomogen mungkin), dan yang tidak, memiliki yang lain.
Sekarang dari atas, kita sampai pada aturan umum seperti di bawah ini
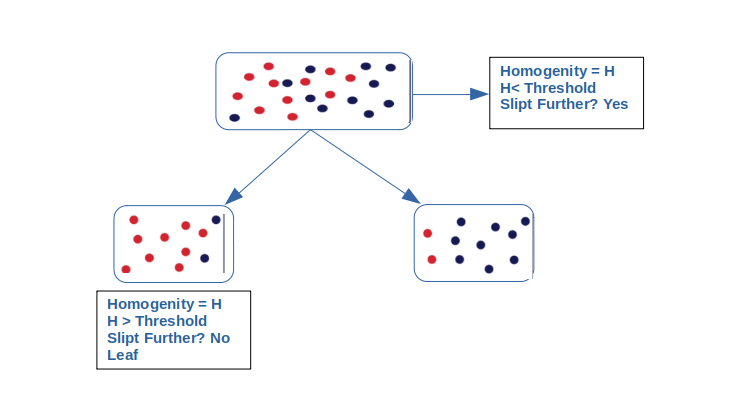 Homogenitas
Homogenitas
Aturannya mengatakan bahwa kami terus membelah data sampai homogenitas data di bawah ambang batas tertentu, jadi Anda pergi selangkah demi selangkah, memilih atribut dan memisahkan data sedemikian rupa sehingga homogenitas meningkat setelah setiap pemisahan. Anda berhenti membelah ketika daun yang dihasilkan cukup homogen. Apa yang cukup homogen? Nah, Anda menentukan jumlah homogenitas yang, ketika tercapai, pohon harus berhenti membelah lebih jauh. Mari kita lihat beberapa metode khusus yang digunakan untuk mengukur homogenitas.
Mari kita coba memahami semua ukuran homogenitas dengan contoh kumpulan data hipotetis
Kita perlu memprediksi untuk sekelompok orang tertentu tergantung pada usia dan jenis kelamin mereka, apakah mereka akan bisa bermain kriket atau tidak.
 Contoh
Contoh
Sekarang dalam contoh di atas, kita perlu memutuskan apakah akan membaginya berdasarkan usia atau jenis kelamin untuk memutuskan apakah orang tersebut dapat bermain kriket atau tidak? Mari kita lihat ukuran homogenitas untuk membuat keputusan
Indeks Gini
Indeks Gini menggunakan jumlah kuadrat dari probabilitas berbagai label dalam kumpulan data.
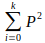 Gini
Gini
Total indeks Gini, jika Anda membagi berdasarkan jenis kelamin, akan menjadi
Indeks Gini(gender) = (fraksi dari total observasi pada node laki-laki)*Indeks Gini pada node pria + (fraksi dari total observasi pada node wanita)*Indeks Gini pada node wanita.
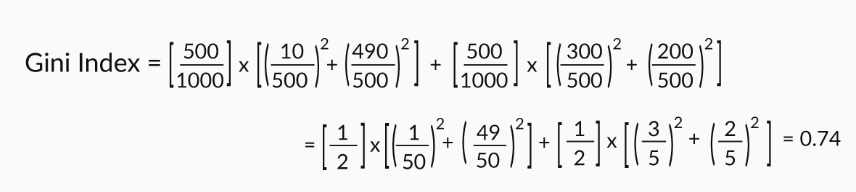 Indeks Gini untuk Pemisahan Gender
Indeks Gini untuk Pemisahan Gender
Demikian pula, kita dapat menghitung indeks Gini jika kita membagi usia.
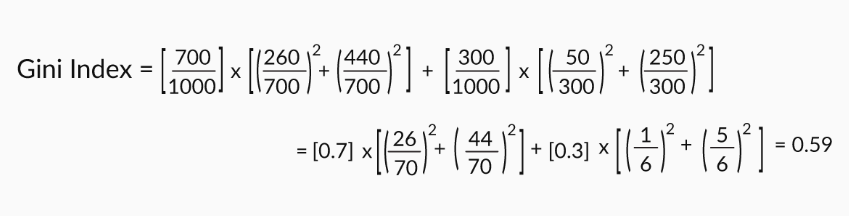 Indeks Gini untuk Pembagian usia
Indeks Gini untuk Pembagian usia
Misalnya Anda memiliki kumpulan data dengan 2 label kelas. Jika kumpulan data benar-benar homogen (semua titik data termasuk dalam label 1), maka probabilitas menemukan titik data yang sesuai dengan label 2 adalah 0 dan label 1 adalah 1. Jadi p1= 1, dan p2= 0. Indeks Gini, sama dengan 1, akan menjadi yang tertinggi dalam kasus seperti itu. Semakin tinggi homogenitas, semakin tinggi indeks Gini.
Jadi jika Anda harus memilih antara dua pemisahan: usia dan jenis kelamin. Indeks Gini pemisahan berdasarkan jenis kelamin lebih tinggi daripada indeks pemisahan usia; jadi Anda pergi ke depan dan membagi gender.
Entropi dan Keuntungan Informasi
Ukuran homogenitas lainnya adalah Information Gain. Idenya adalah menggunakan gagasan entropi. Entropi mengkuantifikasi tingkat ketidakteraturan dalam data, dan seperti indeks Gini, nilainya juga bervariasi dari 0 hingga 1.
Entropi diberikan oleh
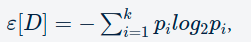 Entropi
Entropi
di mana p _i adalah peluang menemukan titik dengan label i, sama seperti pada indeks Gini dan k adalah jumlah label yang berbeda, dan[D] adalah entropi dari kumpulan data D.
Perolehan Informasi =[D]-ε[DA] yaitu entropi dataset asli dikurangi jumlah bobot entropi partisi setelah Anda membuat pemisahan.
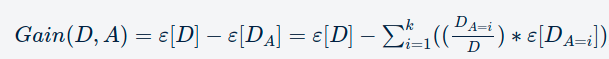 Perolehan Informasi
Perolehan Informasi
Mari kita pertimbangkan sebuah contoh. Anda memiliki empat titik data yang dua di antaranya termasuk dalam label kelas ‘1’, dan dua lainnya termasuk dalam label kelas ‘2’. Anda membagi titik-titik sedemikian rupa sehingga partisi kiri memiliki dua titik data milik label ‘1’, dan partisi kanan memiliki dua titik data lainnya milik label ‘2’. Sekarang mari kita asumsikan bahwa Anda membagi beberapa atribut yang disebut ‘A’.
Entropi kumpulan data asli/induk adalah[D]=−[(24)log2(24)+(24)log2(24)]=1.0. Entropi partisi setelah pemisahan adalah[DA]=−0,5∗log2(2/2)−0,5∗log2(2/2)=0. Keuntungan informasi setelah pemisahan adalah Keuntungan[D,A]=[D]-ε[DA]=1.0.
Jadi, information gain setelah pemisahan kumpulan data asli pada atribut ‘A’ adalah 1,0, dan semakin baik nilai information gain, semakin baik pula homogenitas data setelah pemisahan.
Untuk pemisahan yang dilakukan untuk variabel keluaran berkelanjutan? Anda menghitung Rkuadrat kumpulan data (sebelum dan sesudah pemisahan) dengan cara yang mirip dengan apa yang Anda lakukan untuk model regresi linier. Jadi pisahkan data sedemikian rupa sehingga R2 dari partisi yang diperoleh setelah pemisahan lebih besar dari kumpulan data asli atau induknya. Dengan kata lain, kecocokan model harus ‘baik’ mungkin setelah pemisahan.
Saya harap blog ini akan membuat Anda memahami Pohon Keputusan dengan cara yang sangat sederhana. Blog berikutnya dalam seri ini kita akan membahas hyperparameter yang terkait dengan pohon keputusan dan juga memahami bahwa “Apa yang begitu acak tentang Hutan Acak :)”
Referensi
http://ogrisel.github.io/scikit-learn.org/sklearn-tutorial/modules/tree.html https://www.udemy.com/course/complete-data-science-and-machine-learning-using -python/ Program Ilmu Data oleh Upgrade(https://www.upgrad.com/)
Tautan ke profil media saya
https://commondatascientist.medium.com/medium-to-bond-de3c81e193b8
Understanding Tree Models awalnya diterbitkan di Towards AI on Medium, di mana orang-orang melanjutkan percakapan dengan menyoroti dan menanggapi cerita ini.
Diterbitkan melalui Menuju AI