

Pengarang: Alison Yuhan Yao
Statistik
Contoh termudah untuk intuisi & CLT yang divisualisasikan dengan Python

Semua kode visualisasi dan perhitungan untuk mean dan sd ada di notebook GitHub ini.
Central Limit Theorem (CLT) adalah salah satu teorema yang paling penting dan paling indah dalam Statistik dan Ilmu Data. Di blog ini, saya akan menjelaskan contoh sederhana dan intuitif tentang distribusi sarana dan memvisualisasikan CLT menggunakan python.
Mari kita mulai dari dasar.
Distribusi Mean vs Distribusi Skor
Ketika kita berbicara tentang statistik, kebanyakan orang berpikir tentang distribusi skor. Artinya, jika kita memiliki 6, 34, 11, 98, 52, 34, 13, 4, 48, 68, kita dapat menghitung rata-rata dari 10 skor:
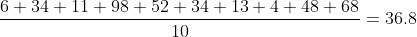
dan selanjutnya, simpangan baku populasi adalah:
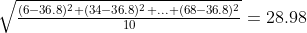
Distribusi sarana, di sisi lain, melihat kelompok 2 atau 3 atau lebih skor dalam sampel. Misalnya, jika kita mengelompokkan skor karena kenyamanan, kita dapat memiliki 6 dan 34 sebagai grup 1, 11 dan 98 sebagai grup 2, dan seterusnya. Kami melihat rata-rata semua grup, yaitu (6+34)/2=10, (11+98)/2 = 54,5, dst. Kemudian, kami menghitung rata-rata distribusi 5 rata-rata, yang seharusnya sama dengan rerata distribusi skor 36,8.
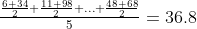
Oleh karena itu, Anda dapat membayangkan distribusi skor sebagai mempelajari 6, 34, 11, 98, 52, 34, 13, 4, 48, 68 (10 skor) dan distribusi sarana sebagai mempelajari 10, 54,5, 43, 8,5, 58 (5 berarti).
Tapi tentu saja, jenis skor pengelompokan 2 ini hanya untuk demonstrasi. Pada kenyataannya, kami melakukan bootstrap (pengambilan sampel acak dengan penggantian) dari 10 skor dan memiliki jumlah grup yang tidak terbatas dengan ukuran N yang sama.
Selanjutnya, mari selami contoh koin sederhana.
CLT divisualisasikan dengan contoh
Kesalahpahaman tentang CLT
Misalkan kita memiliki 1000 koin yang adil dan kita menunjukkan kepala sebagai 1 dan ekor sebagai 0. Jika saya membalik setiap koin sekali, idealnya kita akan mendapatkan distribusi seperti ini:
 Gambar oleh Penulis
Gambar oleh Penulis
Saya tekankan idealnya karena pada kenyataannya, seseorang mungkin dengan mudah berakhir dengan perpecahan 501/499 atau 490/510.
Jadi mengapa 500/500 ideal? Tampaknya cukup mudah untuk memahami ini secara intuitif. Bagaimana kita bisa membuktikan ini secara matematis?
Untuk menjawabnya, kita perlu berbicara sedikit tentang probabilitas.
Probabilitas berkaitan dengan memprediksi kemungkinan peristiwa masa depan, sementara statistik melibatkan analisis frekuensi peristiwa masa lalu. [1]
Sebelum itu, kami telah berbicara secara ketat tentang statistik karena kami melihat hasil eksperimen dan menghitung head and tails. Namun, ketika meramalkan kasus ideal di mana kepala dan ekor sama-sama terbelah, kami memprediksi kemungkinan apa yang seharusnya terjadi ketika ukuran sampel sangat besar. Dan apa yang seharusnya terjadi konsisten dengan kemungkinan sesuatu terjadi berkat Hukum Bilangan Besar. Harap dicatat bahwa untuk menggunakan LLG, ukuran sampel harus sangat besar.
Sebagai ilustrasi, mari kita lakukan eksperimen lain dengan koin yang adil, tetapi kali ini kita memiliki 100000000000 koin. Apa yang Anda harapkan terjadi? Sekali lagi, kami idealnya akan mendapatkan distribusi seperti ini:
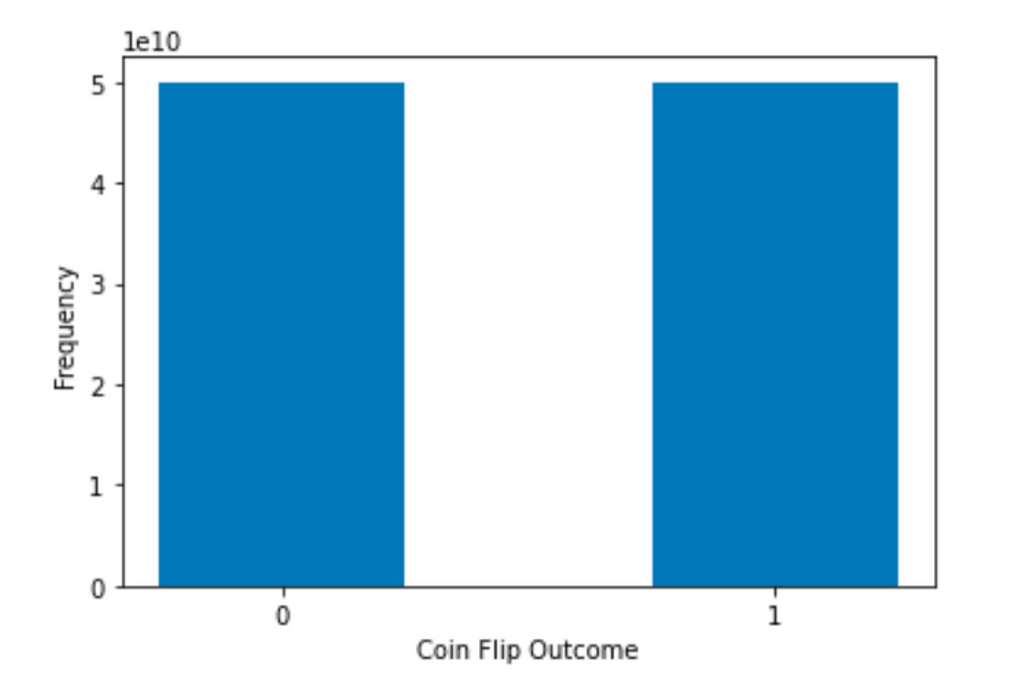 Gambar oleh Penulis
Gambar oleh Penulis
Itu karena, untuk koin yang adil, peluang melempar kepala atau ekor adalah sama, yaitu 0,5. Jadi kami mengharapkan hasil aktual mendekati setengah-setengah ketika ukuran sampel jauh lebih besar.
Hal lain yang sangat penting di sini adalah bahwa meningkatkan ukuran sampel tidak mengubah bentuk distribusi skor!
Tidak peduli berapa banyak koin yang dilempar, hasilnya tidak akan pernah menjadi distribusi normal karena CLT adalah tentang distribusi sarana, bukan distribusi skor.
Kita dapat dengan mudah menghitung mean dan standar deviasi sesuai dengan distribusi skor tak terbatas. Ketika kita melempar n koin yang adil (n menuju tak terhingga), kita akan memiliki n/2 kepala dan n/2 ekor.
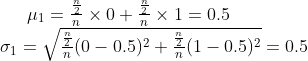
CLT Divisualisasikan
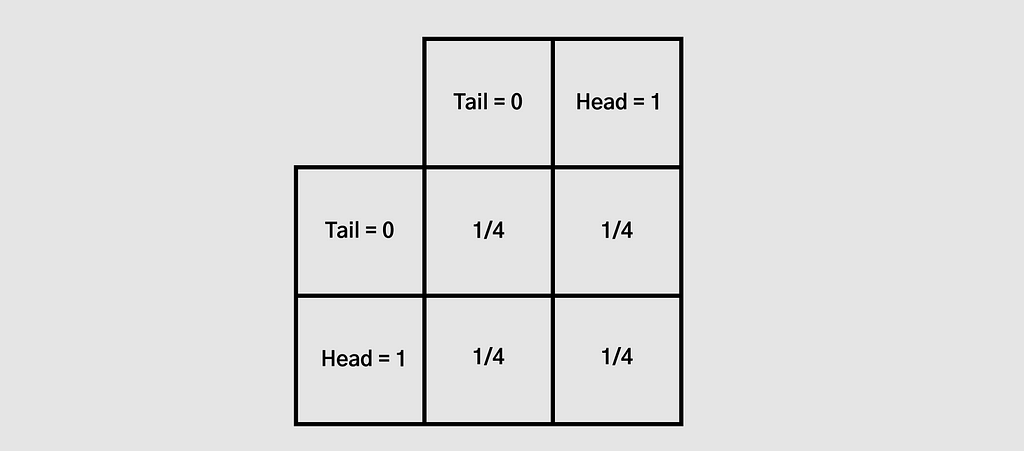
Sekarang, kita melihat cara pasangan koin, artinya kita mengelompokkan 2 koin bersama dan memiliki jumlah grup 2 koin yang tak terbatas. Kemungkinan cara dari 2 koin adalah 0, 0,5, dan 1.
 Gambar oleh Penulis
Gambar oleh Penulis
Probabilitas koin pertama menjadi ekor dan koin kedua menjadi ekor adalah 1/2 * 1/2 = 1/4. Seperti tiga lainnya.
Oleh karena itu, peluang untuk mendapatkan rata-rata 0 (kedua ekor) adalah 1/4. Peluang terambil rata-rata 0,5 (satu ekor dan satu kepala) adalah 1/4 * 2= 1/2. Probabilitas untuk mendapatkan rata-rata 1 (kedua kepala) juga 1/4.
 Gambar oleh Penulis
Gambar oleh Penulis
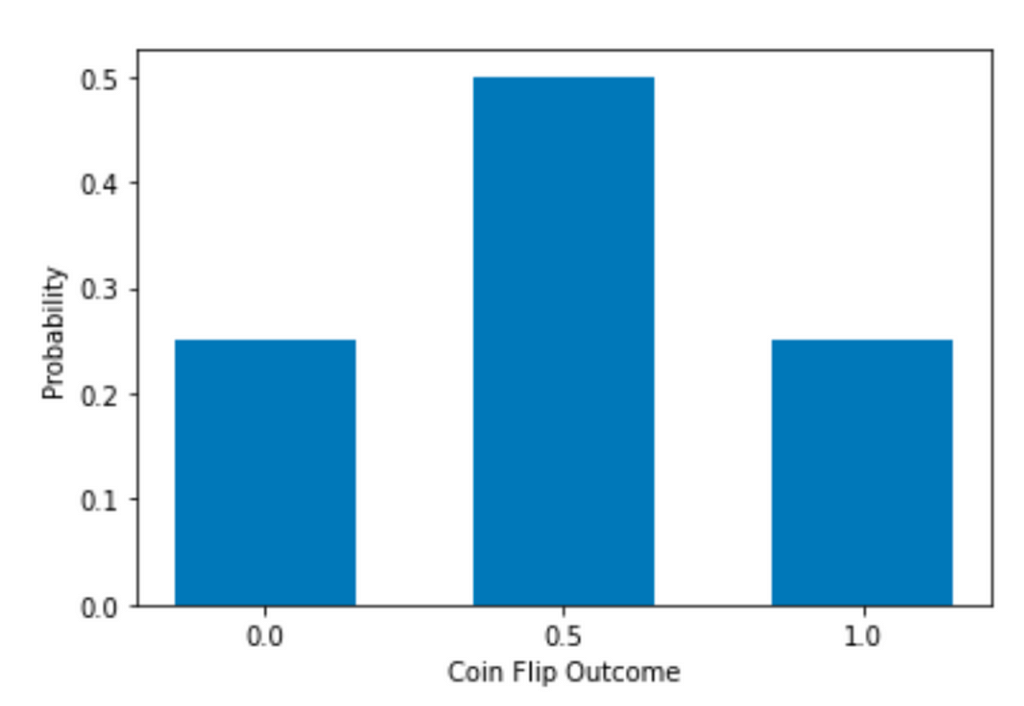
Kemudian, distribusinya akan terlihat seperti ini. Harap dicatat bahwa sumbu y sekarang adalah Probabilitas, bukan Frekuensi (alias hitungan), tetapi bentuknya sama tidak peduli sumbu y mana yang Anda gunakan. Dibandingkan dengan grafik batang sebelumnya, kami sekarang memiliki 3 batang dengan puncak di tengah.
Sekali lagi, kami menghitung mean dan standar deviasi:

Rata-rata tetap sama, tetapi sd lebih kecil sekarang.
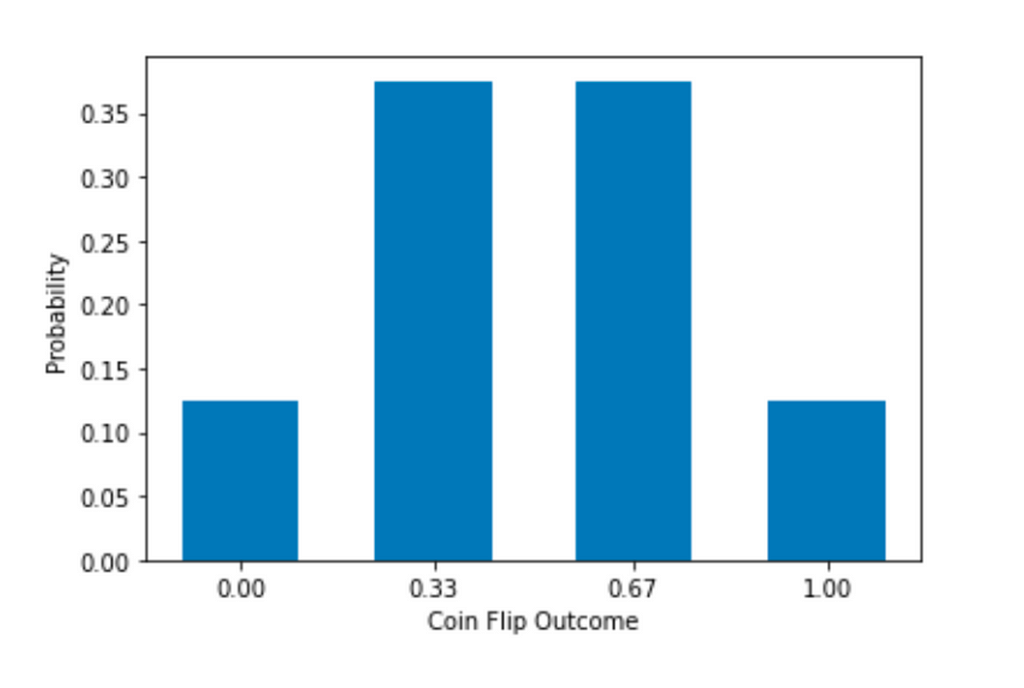
Demikian pula, kita dapat mengelompokkan 3 koin bersama. Kemungkinan cara dari 3 koin sekarang adalah 0, 1/3, 2/3, dan 1. Ada total 2 * 2 * 2 = 8 kombinasi.
 Gambar oleh Penulis
Gambar oleh Penulis
Peluang mendapatkan mean 0 adalah p(0) = 1/8.
Demikian pula,
p(0,33) = p(0,67) = 3/8 dan
p(1) = 1/8.
Rata-rata dan simpangan bakunya adalah:
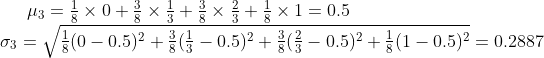
 Gambar oleh Penulis
Gambar oleh Penulis
Distribusi sekarang memiliki 4 bar, 1 lebih banyak dari yang sebelumnya, lagi. Mean tetap sama dan sd menurun.
Itu sepertinya sebuah pola.
Apa yang akan terjadi pada mean, simpangan baku, dan distribusi jika kita menaikkan nilai N?
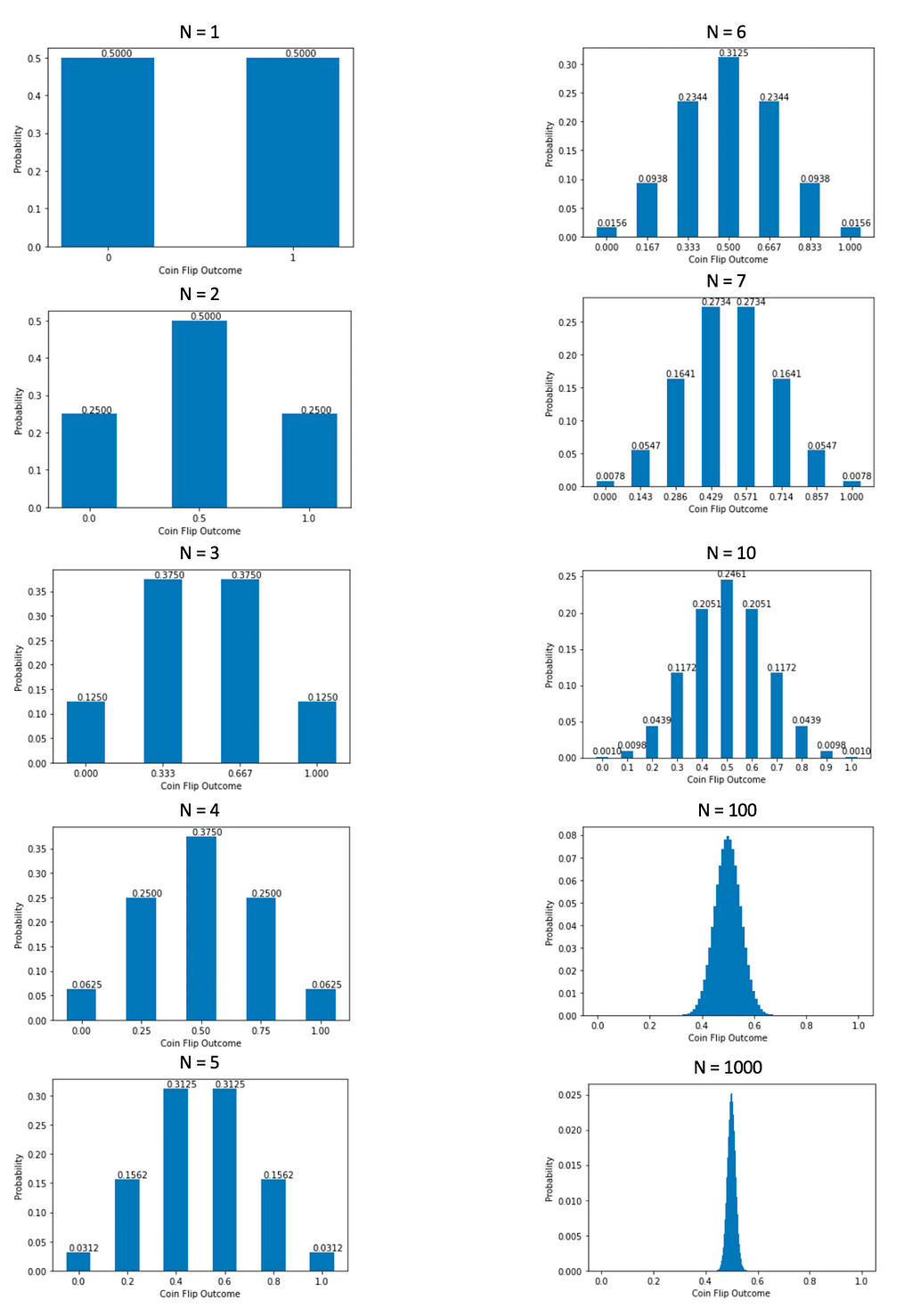
Untuk melihat apakah itu memang sebuah pola, saya menghitung dan memvisualisasikan lebih banyak hasil. Angka N di bawah ini adalah jumlah koin di setiap kelompok. Distribusi skor menyiratkan N = 1.
 Gambar oleh Penulis
Gambar oleh Penulis
Sekarang, mudah untuk melihat bahwa ketika N menjadi lebih besar, distribusi rata-rata semakin mendekati distribusi normal berbentuk lonceng. Ketika N sangat besar, kita hampir tidak dapat melihat palang di samping karena probabilitasnya terlalu kecil, tetapi cara yang mungkin masih berkisar dari 0 hingga 1.
Kita juga dapat melihat bahwa rata-rata distribusi rata-rata selalu 0,5, sedangkan standar deviasi dari distribusi rata-rata terus menurun karena bentuk yang terlihat semakin menyempit.
Kesalahan Standar
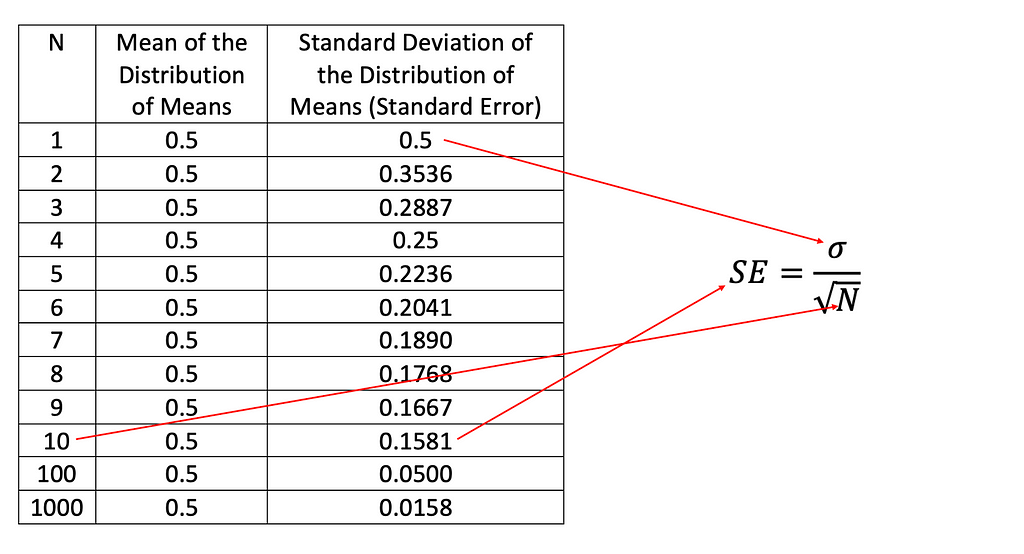
Kami sebenarnya memiliki cara untuk mengukur perubahan dalam standar deviasi sebagai N menjadi lebih besar. Saya menulis kode python berikut untuk menghitung mean dan standar deviasi.
https://medium.com/media/d47b6dda865626916fe0575fb7b2e88e/href
 Gambar oleh Penulis
Gambar oleh Penulis
Sekali lagi, kita dapat melihat bahwa mean tetap sama dan sd dari distribusi mean turun ketika N semakin besar. Standar deviasi dari distribusi rata-rata disebut juga standar error (SE) dan hubungan antara SE dan N adalah SE = sigma/akar kuadrat dari N. Dalam hal ini, sigma = 0,5 karena ketika N=1, alias ketika kelompok hanya memiliki satu skor, itu adalah distribusi skor. Ketika N sama atau lebih besar dari 2, itu menjadi distribusi rata-rata. Dan jika N bertambah, penyebut SE bertambah, maka SE berkurang.
Kesimpulan
Sebagai penutup, kami telah mempelajari contoh koin dengan cermat dan mempelajari poin-poin berikut:
Distribusi skor berbeda dengan distribusi rata-rata. CLT menggunakan distribusi rata-rata untuk mendapatkan distribusi normal ketika jumlah skor untuk menghitung rata-rata (N) sangat besar. Tidak peduli seberapa besar ukuran sampel, distribusi skor tidak akan normal. Rata-rata distribusi rata-rata sama dengan rata-rata distribusi skor. Standar deviasi dari distribusi rata-rata, alias kesalahan standar, berkurang dengan meningkatnya jumlah skor untuk menghitung rata-rata (N). Dan hubungan yang tepat adalah:
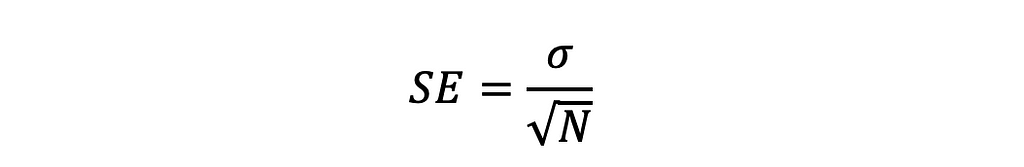
Semua kode visualisasi dan perhitungan untuk mean dan sd ada di notebook GitHub ini.
Terima kasih telah membaca! Saya harap ini telah membantu Anda.
Terima kasih khusus kepada Profesor PJ Henry untuk memperkenalkan contoh koin di kelas. Saya telah memodifikasinya dan menambahkan penjelasan dan visualisasi saya sendiri di sini.
Referensi
[1] Steve Skiena, “Probabilitas versus Statistik”, Taruhan Terhitung: Komputer, Perjudian, dan Pemodelan Matematika untuk Menang! (2001), Cambridge University Press dan Asosiasi Matematika Amerika
Intuisi di balik Teorema Batas Pusat awalnya diterbitkan di Towards AI on Medium, di mana orang-orang melanjutkan percakapan dengan menyoroti dan menanggapi cerita ini.
Diterbitkan melalui Menuju AI