

Author(s): Rashmi Margani
Machine Learning
Concept Drift, Data Drift & Monitoring
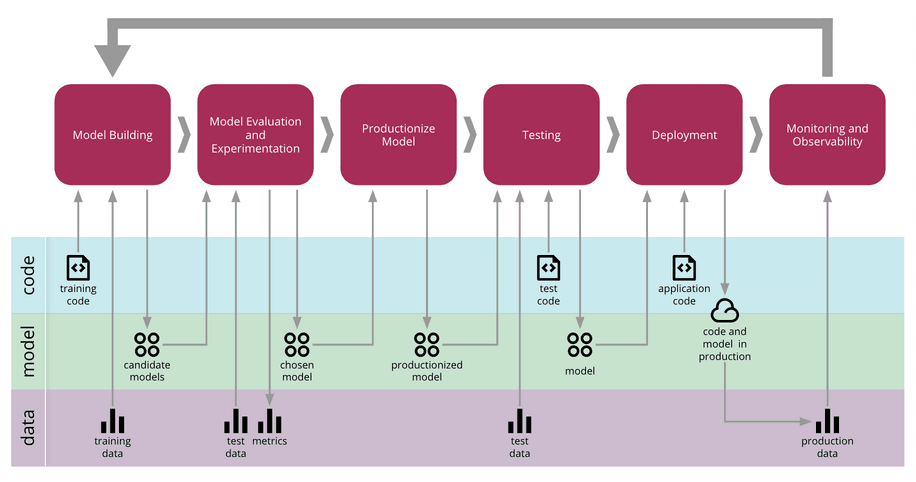 Fig: https://martinfowler.com/ ML System life cycle
Fig: https://martinfowler.com/ ML System life cycle
The most exciting moment of any machine learning system is when you get to deploy your model, but deploying becomes hard due to statistical issues such as “when past model performance is no more guaranteed for future and model performance degrade over a period of time due to changes of data when the model is deployed in a cloud with frequent data changes” and system engine such as system demands monitoring the ML system often which is manual in nature and tedious which needs to be handled through automation as much as possible.
Now, How to deal with the statistical issue or degrading performance of the model?. How to handle the data changes once the model is deployed?
That is where Concept and Data drift comes into the picture.
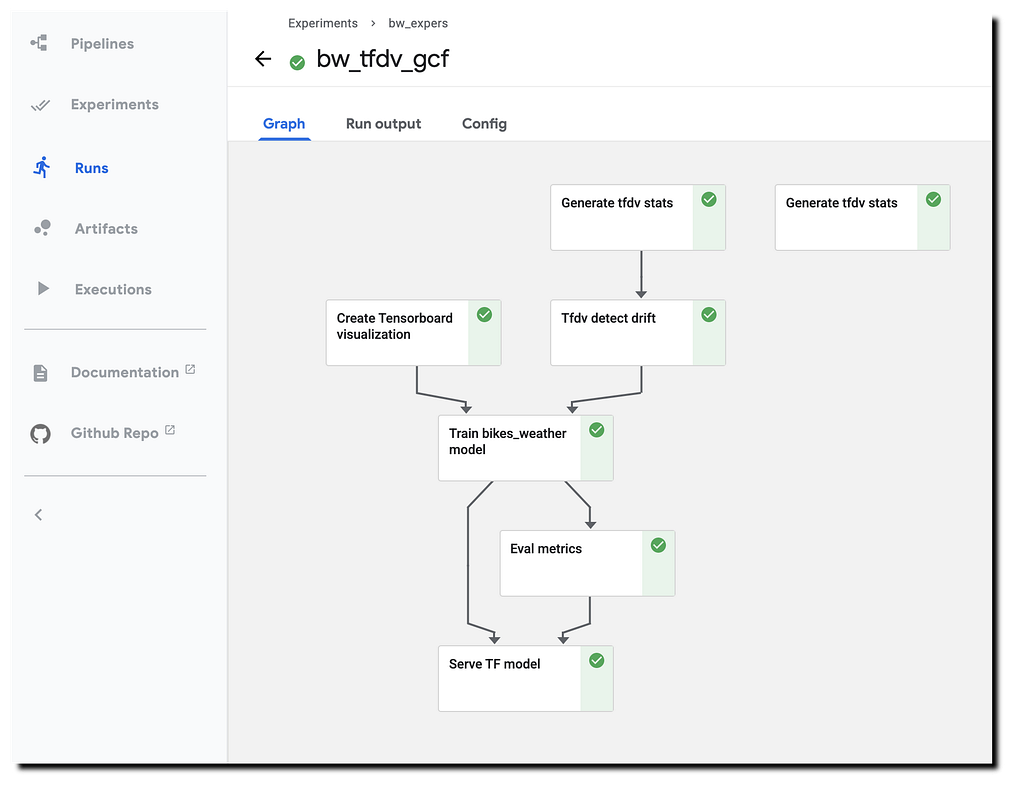 Fig: cloud.google.com TFDV workflow to detect data drift
Fig: cloud.google.com TFDV workflow to detect data drift
Concept Drift refers to if the desired mapping from x to y changes and it leads to inaccurate predictions due to huge data distribution changes in the productized model.
For example, let’s say for a given user, a lot of surprising online purchases, which should have flagged that account for fraud. But to due to COVID-19 those same purchases would not have really been any cause for alarm and the system fails to classify as a fraud as the number of new online purchases increased due to pandemic. That credit card may have been stolen.
Another example of Concept drift, let’s say that x is the size of a house property, and y is the price of a house property, because of changes in the market, houses may become more expensive over time. The same size house will end up with a higher price which is concept drift.
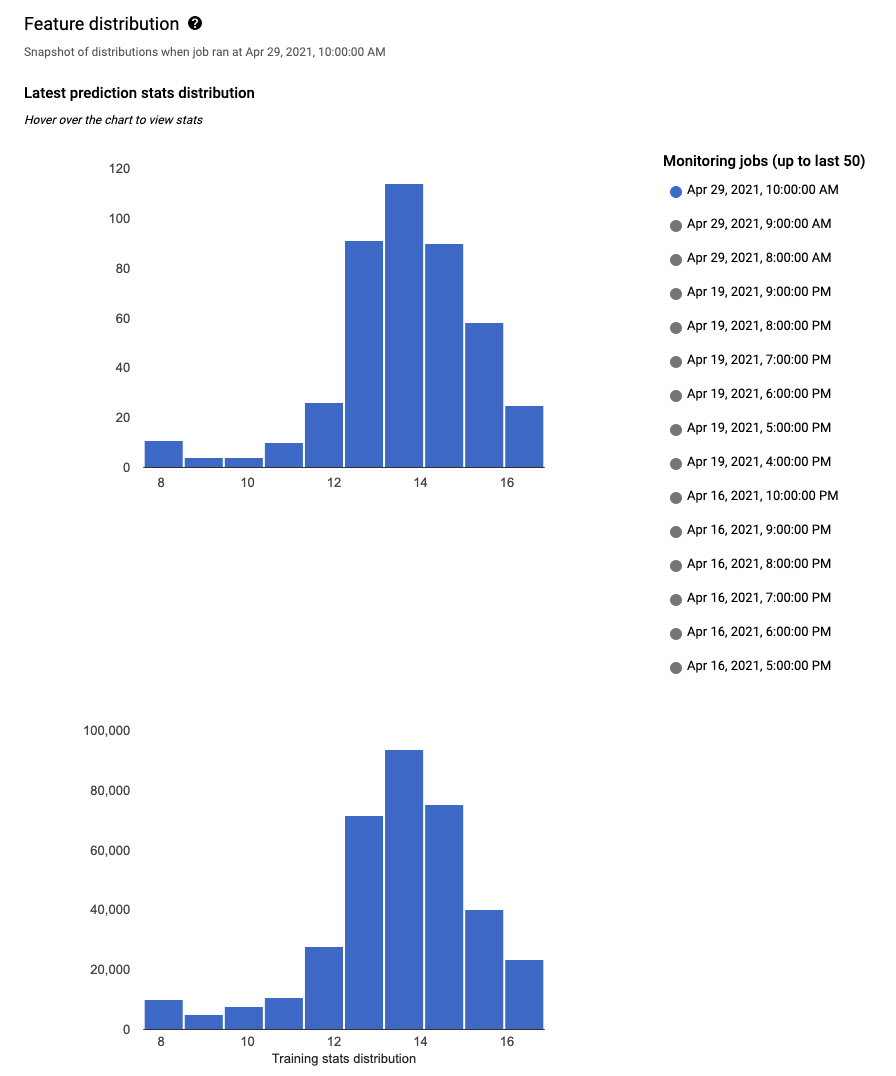 fig: cloud.google.com data distribution histograms allow you to quickly hone in on the changes that occurred in the data, and then determine how to fix it
fig: cloud.google.com data distribution histograms allow you to quickly hone in on the changes that occurred in the data, and then determine how to fix it
Data Drift refers to if the distribution of x changes, even if the mapping from x or y does not change. In addition to managing these changes to the data, that leads to the second set of software engine issues, that you will have to manage/automate the job process to deploy a system successfully.
For example, let’s take the housing property use case again. let’s say, people start building larger houses or start building smaller houses and thus the input distribution of the sizes of houses actually changes over time. When you deploy a machine learning system, one of the most important tasks will often be to make sure you can detect and manage any changes. You are implementing a prediction service whose job it is to take queries x and output prediction y, you have a lot of design choices as to how to implement this piece of software.
Here’s a checklist of questions, that might help you with making the appropriate decisions for dealing with the software engineering issues.
Let’s say questions/checklists such as,
Do you need real-time predictions or are batch predictions? For example, real-time prediction includes take one sequence and make a prediction let’s say for speech recognition. Batch prediction is mostly used in hospitals, let’s say Take electronic health records and run an overnight batch process to see if there’s something associated with the patients, that we can spot.
Does your prediction service run into clouds or run at the edge or maybe even in a Web browser?
How much computing resources do you have or can allocate to a given ML system?
What type of security and privacy setting need to support the ML systems in production?
How many queries and throughput need to be supported given query per second?
How type of logging needs to be implemented to backtrack the ML system failure and to support reproducibility?
There is what you need to do to monitor the system performance and to continue to maintain it, especially in the face of concept drift as well as data drift. When you’re building machine learning systems for the very first deployments, will be quite different compared to when you are updating or maintaining a system that has already previously been deployed.
Because unfortunately, most of the first deployment means you may be only about halfway there, and the second half of your work is just starting only after your first deployment, because even after you’ve deployed there’s a lot of work to feed the data back and maybe to update the model, to keep on maintaining the model whenever there is a change of data.
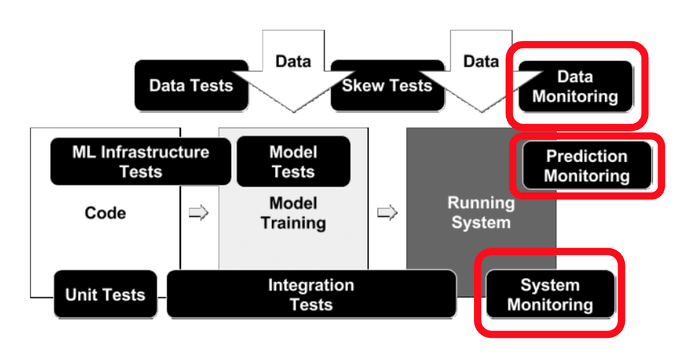 Fig: https://research.google/pubs/pub46555/
Fig: https://research.google/pubs/pub46555/
How to automate the monitoring process for ML systems once it is deployed?.
With a few pioneering exceptions, most tech companies have only been doing ML/AI at scale for a few years, and many are only just beginning the long journey. This means that:
The challenges are often misunderstood or completely overlooked
The frameworks and tooling are rapidly changing (both for data science and MLOps)
The best practices are often grey
Checklist/Strategies to handle the monitoring ML system includes such as,
1. Do dependency changes result in notification?
2. Do data invariants hold in training and serving inputs, i.e. monitor Training/Serving Skew?
3. Do training and serving features compute the same values always?
4. Is the model deployed is numerically stable?
5. Do the model has not experienced dramatic or slow-leak regressions in training speed, serving latency, throughput, or RAM usage?
6. Is the model has not experienced a regression in prediction quality on served data?
In the next series, will see practical implementation and various techniques to deal with data drift and concept drift, How to make it a practice in the development phase so that maintaining becomes easier post deploying the model into production.
Deployment ML-OPS Guide Series – 2 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI