

Pengarang: Fabio Chiusano
Awalnya diterbitkan di Towards AI the World’s Leading AI and Technology News and Media Company. Jika Anda sedang membangun produk atau layanan terkait AI, kami mengundang Anda untuk mempertimbangkan untuk menjadi sponsor AI. Di Towards AI, kami membantu menskalakan AI dan startup teknologi. Biarkan kami membantu Anda melepaskan teknologi Anda kepada massa.
 Foto oleh Gabriel Sollmann di Unsplash
Foto oleh Gabriel Sollmann di Unsplash
Pemrosesan Bahasa Alami
Dari pembuatan set pelatihan hingga model terlatih
Topic Tagging adalah proses menetapkan topik ke konten dari berbagai bentuk, yang paling menyebar adalah teks. Kami biasanya melihat artikel yang ditandai di surat kabar oleh penulis sebagai bentuk pengorganisasian pengetahuan dan untuk membuat konten lebih mudah ditemukan oleh audiens yang paling menginginkannya. Selain itu, dapat digunakan untuk menganalisis sejumlah besar data teks, seperti aliran artikel dari blog internet (di mana setiap blog menggunakan tag yang berbeda atau tidak menggunakannya sama sekali) atau menyukai posting sosial.
Penandaan Topik Ekstraktif vs Prediktif
Kita dapat membedakan antara dua jenis penandaan topik. Mari kita perhatikan teks berikut sebagai contoh:
Cryptocurrency memungkinkan Anda membeli barang dan jasa, atau memperdagangkannya untuk mendapatkan keuntungan. Berikut lebih lanjut tentang apa itu cryptocurrency, cara membelinya, dan cara melindungi diri Anda sendiri.
Penandaan Topik Ekstraktif bekerja dengan mendeteksi kata kunci yang terkandung dalam teks dan menggunakan bentuk normalnya sebagai topik. Seringkali topik ini diperkaya menggunakan kategori dari basis pengetahuan sumber terbuka seperti Wiki Data. Topik yang diprediksi untuk contoh sebelumnya adalah seperti Uang, Bisnis, Pemberian, Upah, Harga, Bantuan, Pembeli, Pekerjaan, Toko, Layanan. Pemberian Tag Topik Prediktif bekerja dengan serangkaian topik yang telah ditentukan sebelumnya, dengan melatih model klasifikasi dengan beberapa contoh teks untuk setiap topik. Set pelatihan dapat diambil dari web karena setiap artikel yang diterbitkan dengan tag adalah sampel pelatihan potensial. Topik yang diprediksi untuk contohnya adalah sesuatu seperti Bitcoin, Cryptocurrency, Crypto, Teknologi Blockchain, Kriptografi, Perdagangan, Keamanan Siber, Keamanan Informasi, Keamanan, Keselamatan, Privasi, Blockchain, Ekonomi, Ekonomi.
Berikut adalah perbandingan singkat untuk penandaan topik ekstraktif dan prediktif, dengan pro dan kontra.
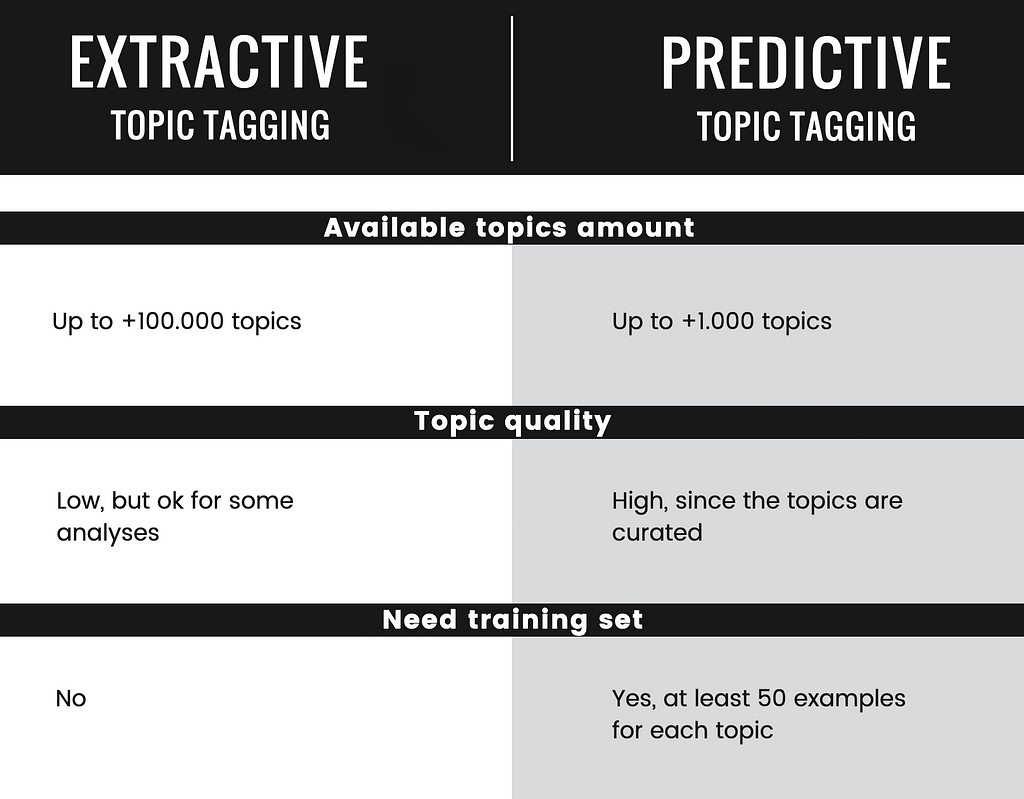 Perbandingan penandaan topik ekstraktif dan prediktif. Gambar oleh penulis.
Perbandingan penandaan topik ekstraktif dan prediktif. Gambar oleh penulis.
Karena tujuan artikel ini adalah untuk mengajarkan cara memprediksi topik berkualitas tinggi, kami akan fokus pada cara melakukan Pemberian Tag Topik Prediktif. Untuk melatih model penandaan topik, kita membutuhkan data pelatihan. Misalnya, artikel yang diterbitkan secara online dengan tag yang terkait dengan penulisnya, yang memastikan bahwa data memiliki kualitas yang baik. Medium adalah sumber yang bagus untuk artikel semacam itu, mari kita mengikis Medium untuk membangun satu set pelatihan. Kode lengkapnya dapat ditemukan di Colab ini.
Scraping Medium untuk mendapatkan data pelatihan
Kita memerlukan koran3k untuk mengekstrak data artikel dari HTML dan langdetect untuk menyimpan hanya artikel berbahasa Inggris.
https://medium.com/media/21fd8629549a203092a820c1b895f0c8/href
Langkah selanjutnya adalah mendefinisikan fungsi yang menggores artikel dari URL-nya, mem-parsingnya dengan koran3k untuk mengekstrak judul dan konten teksnya, dan mendapatkan tag artikel dengan beberapa heuristik.
https://medium.com/media/064497b99cda82bbca499adbf79b4a49/href
Sekarang kita tahu cara mengikis artikel dari URL, kita memerlukan tempat untuk menemukan semua artikel dengan tag yang kita minati. Untuk tujuan ini, kita dapat mengikis halaman arsip Medium yang diatur berdasarkan tag dan tanggal . Misalnya, halaman arsip topik Artificial Intelligence untuk tanggal 15 Januari 2020 adalah https://medium.com/tag/artificial-intelligence/archive/2020/01/15. Kami dapat menggeneralisasi struktur URL sebagai https://medium.com/tag/
https://medium.com/media/010f9b973f1cdc9086e530b4f44bf5b6/href
Mari kita tentukan beberapa tag untuk dikikis, kita mulai dengan enam ini.
https://medium.com/media/da3a89e2450a6cf40f06e6508e009995/href
Sekarang kita dapat menyatukan semua bagian dan mulai mengumpulkan 50 artikel untuk setiap tag. Ingatlah untuk melakukan pengikisan lembut dan tunggu beberapa saat di antara permintaan!
https://medium.com/media/2e7a2ecf740af8b4c996521becbca839/href
Akhirnya, kami menyimpan artikel yang tergores dalam kerangka data Pandas. Ini akan berguna di bagian selanjutnya untuk melatih model pembelajaran mesin kami.
https://medium.com/media/9a42c9ba49ddb49778ffbe65118e6074/href
Melatih model Pemberian Tag Topik
Kita memerlukan Pandas dan NumPy untuk manipulasi data, NLTK untuk menormalkan teks, dan Sklearn untuk model pembelajaran mesin.
https://medium.com/media/c3facfe71e5326fb1bc23def78adb557/href
Ini adalah bagaimana kerangka data kami dengan data yang tergores akan terlihat seperti.
 Kerangka data Pandas berisi artikel dengan tag. Gambar oleh penulis.
Kerangka data Pandas berisi artikel dengan tag. Gambar oleh penulis.
Hal pertama yang harus dilakukan adalah menghapus dari artikel yang tergores semua tag yang tidak kami kikis (yaitu kami hanya menyimpan enam tag yang kami definisikan sebelumnya karena hanya mereka yang memiliki data yang cukup untuk melatih model) dan menerapkan MultiLabelBinarizer pada tag untuk mengonversinya ke format multilabel yang didukung.
https://medium.com/media/e9133329f3570542475ad64a639dc930/href
Sebagai gambaran, ini adalah contoh cara kerja MultiLabelBinarizer, diambil dari dokumentasi Sklearn.
>>> mlb.fit_transform([{‘sci-fi’, ‘thriller’}, {‘comedy’}])
Himpunan([[0, 1, 1],
[1, 0, 0]])
>>> daftar (mlb.classes_)
[‘comedy’, ‘sci-fi’, ‘thriller’]
Kita sekarang dapat menyiapkan data untuk model kita. Model akan memprediksi topik dari judul dan teks artikel, yang kami gabungkan. Teks ini kemudian dibersihkan dengan pemrosesan teks standar seperti mengubahnya menjadi huruf kecil, mengganti karakter buruk, dan menghapus stopwords.
Teks yang dibersihkan kemudian diubah oleh TfidfVectorizer. Selain umum digunakan dalam pencarian informasi, TF-IDF juga berguna dalam klasifikasi dokumen. Memanfaatkan TF-IDF alih-alih frekuensi token mentah dalam dokumen mengurangi dampak token yang sangat sering terjadi dan oleh karena itu secara empiris kurang informatif daripada token yang muncul di sebagian kecil dokumen.
https://medium.com/media/7d58980c569f9ddba4708e91bcfd641b/href
Sekarang setelah kami menyiapkan data pelatihan, kami dapat melatih model kami. Masalah kami adalah masalah klasifikasi multilabel, yaitu, kami ingin memberi label setiap sampel dengan subset dari semua label yang mungkin. Kita dapat melakukan ini dengan melatih pengklasifikasi biner untuk setiap topik, persis seperti yang dilakukan MultiOutputClassifier.
https://medium.com/media/eb7789d8247431dbb0777f051b3c9d65/href
Kami berada di akhir! Mari kita coba modelnya dengan beberapa kalimat tiruan.
 Model yang terlatih berhasil memprediksi topik Kecerdasan Buatan dan Pemrograman. Gambar oleh penulis.
Model yang terlatih berhasil memprediksi topik Kecerdasan Buatan dan Pemrograman. Gambar oleh penulis.
 Model terlatih berhasil memprediksi topik Media Sosial. Gambar oleh penulis.
Model terlatih berhasil memprediksi topik Media Sosial. Gambar oleh penulis.
Topik yang diprediksi konsisten dengan input teks. Kerja yang baik!
Kemungkinan peningkatan
Dalam tutorial ini, kita sampai pada intinya, tetapi ada banyak aspek yang kita abaikan.
Evaluasi model dengan metrik yang sesuai dan uji validasi latih untuk membagi set data. Kita harus mengevaluasi presisi, daya ingat, dan skor F1 dari model sehingga kita tahu apakah perubahan pada model itu bermanfaat. Biasanya, F1-score digunakan sebagai metrik untuk dioptimalkan dalam pengaturan klasifikasi multilabel, tetapi Anda harus memilih metrik sesuai dengan kasus penggunaan model. Misalnya, jika model membantu manusia dalam menetapkan kategori ke artikel, penarikan mungkin lebih penting daripada presisi karena selalu ada orang yang dapat memperbaiki kesalahan prediksi. Sempurnakan ambang klasifikasi dari setiap pengklasifikasi biner. Ingatlah untuk mengubah parameter ini pada set validasi untuk mengoptimalkan metrik Anda. Dapatkan data pelatihan dari beberapa situs web. Dalam tutorial ini, kami hanya menggores Medium, tetapi ada banyak situs web lain untuk mengumpulkan data. Persiapan data pelatihan yang lebih baik dengan taksonomi. Kami para ilmuwan data cenderung bekerja terlalu banyak pada model dan sedikit pada kualitas data. Set pelatihan kami terdiri dari artikel dan tag yang diberikan oleh penulisnya masing-masing, tetapi penulis sering kali dibatasi dalam jumlah tag yang dapat diberikan. Ini berarti bahwa penulis sering kali harus memilih tag mana yang akan ditetapkan di antara banyak tag yang masuk akal, menurut beberapa logika visibilitas tag dan kekhususannya. Akibatnya, set pelatihan kami kotor karena ada tag yang masuk akal yang tidak ditetapkan ke artikel! Untuk mengatasi masalah ini, kita dapat membuat taksonomi topik dan membersihkan dataset dengannya, menetapkan lebih banyak tag umum setiap kali kita melihat tag yang lebih spesifik ditetapkan. Misalnya, jika sebuah artikel memiliki tag Machine Learning, kita dapat menyimpulkan bahwa artikel tersebut juga berbicara tentang Artificial Intelligence, karena Artificial Intelligence adalah hiperonim dari Machine Learning.
Contoh kasus penggunaan Pemberian Tag Topik
Dalam artikel lain ini, saya menggores bagian blog dari situs web perusahaan terkenal dan menerapkan penandaan topik untuk menganalisis apa yang ditulis oleh perusahaan tersebut.
Kesimpulan
Tagging Topik Prediktif adalah solusi untuk memprediksi topik berkualitas tinggi ke artikel dan agak mudah untuk melatih model dengan kualitas yang layak. Namun, menurut pengalaman saya, tindakan yang diusulkan di bagian kemungkinan perbaikan secara dramatis meningkatkan kualitas model akhir. Kemungkinan kasus penggunaan berasal dari analisis otomatis sejumlah besar teks, seperti analisis media sosial atau analisis pesaing.
Terima kasih telah meluangkan waktu untuk membaca artikel ini. Pastikan untuk bertepuk tangan posting ini jika Anda menikmatinya dan ingin melihat lebih banyak!
 Logo NL Planet.
Logo NL Planet.
Tetap up to date dengan cerita terbaru tentang Pemrosesan Bahasa Alami yang diterapkan dan bergabunglah dengan komunitas NLPlanet di LinkedIn, Twitter, Facebook, dan Telegram.
Cara melatih model Pemberian Tag Topik untuk menetapkan topik berkualitas tinggi ke artikel awalnya diterbitkan di Towards AI on Medium, di mana orang-orang melanjutkan percakapan dengan menyoroti dan menanggapi cerita ini.
Diterbitkan melalui Menuju AI